학습주제
- Jupyter - DataFrame
주요 학습 내용
- DataFame
- Series는 1차원 구조
- DataFrame은 2차원 구조
- axis = 0 : index 방향
- axis = 1 : columns 방향
- 2개 이상의 Series로 구성된다. https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html
- DataFrame 생성
member = { 'Attack': [111, 222, 333], 'Defence': [444, 555, 666], 'Luck': [777, 888, 999] } member_df = pd.DataFrame(member) member_df
- 열(Columns) 접근
- 데이터가 제공되면 그것으로 columns로 설정한다.
- 제공되지 않으면 default는 Rangeindex(0, 1, 2 ..n)으로 설정된다.

열 접근을 하면 Series가 반환된다.

- index
- 데이터가 제공되면 그것으로 index로 설정된다.
- 제공되지 않으면 default는 RangeIndex(0, 1, 2..n)으로 설정된다.

- 권장하는 방식

- DataFrame의 속성(Attr, attr, attributes)
- . (dot)을 통해 접근하며 활용할 수 있는 속성을 확인해보자- .shape : 행렬 크기(모양)을 알 수 있다.
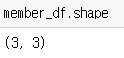
- .info() : 정보를 알 수 있다.

- .values

- .dtypes : 데이터 타입을 알 수 있다.

- .index

- .columns

- .axes : 인덱스 정보와 열 정보를 알 수 있다.

- .sum : 각 열 => 각 Series를 .sum()한 결과로 또 다른 Series를 만든다.
- Series는 .sum()하면 단일 값
- DataFrame을 .sum()하면 Series

- .describe() : 집계함수 요약

- .round(자리수) : 자리수 반올림

- .str.replace() : 포맷 변경하기
- 숫자형 데이터로 변환 가능한 형태로 처리한다.
- 데이터 분석에 유용한 형태로 가공하는 작업이다 (데이터 전처리)
- comma(,)부터 .str.replace()로 삭제하자

삭제 
결과 확인
- .fillna() : 결측치 대체하기

- .astype() : dtype 변환하기
- 정수형 dtype인 int64로 변환한다.

- 정수형 dtype인 int64로 변환한다.
- .quantile()
- 분위수 - 오름차순/내림차순 되있을 때 이를 나누는 지점
- percentiles : 백분위수, 100개 영역 지점이 존재한다. 퍼샌트
- quartiles : 4분위수, 4구역 지점이 존재한다.

q = 가 확인할 지점이다.
- .nlargest(n, columns, keep)

movie_df.sort_values(by = 'IMDB_Rating', ascending=False) 랑 같은 결과가 나온다 쉽게 만든거라 생각하면 편하다 - .nsmallest(n, columns, keep)

- .sort_values()
- https://pandas.pydata.org/docs/reference/api/pandas.Series.sort_values.html
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.sort_values.html
- Series.sort_values보다 Data.sort_values인자가 'by'하나 더 있다.
- Series는 단일 열 이지만, DataFrame은 다중열 이기에 어떤 열을 정렬할 지, 정렬하려는 열 정보가 필요하다.

- .set_index()
- 특정 열을 인덱스로 설정하는 기능을 제공한다.
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.set_index.html

- .reset_index()
- 인덱스를 초기화한다.
- MultiIndex 작업도 초기화한다.

- .drop() : 열 삭제

- .drop() : 행 삭제

- .drop() : 행 삭제(by labels, list-like)

- .drop() : 열 삭제(axis=1)
- axis = 0 : index 방향
- axis = 1 : columns 방향

- .insert() : 추가
- .dropna()
- NaN 유형 데이터를 drop 시킨다.

- NaN 유형 데이터를 drop 시킨다.
- .fillna() : 결측치 대체하기
- .shape : 행렬 크기(모양)을 알 수 있다.


- csv로 DataFrame 생성하기
- df = pd.read_csv(' csv파일')
- 단일 열 접근 -> Series
- type(df[ '열이름' ])
- 다중 열 접근
- type(df['열이름', '열이름2', .. ])
- 집계함수 + axis
- 공간 절약되서 axis='index', axis = 0을 쓰며
- sum()말고도, max, min, mean등의 집계합수와 axis를 사용해보면
 |
 |
- DataFrame 집계함수에서 숫자형 데이터만 있지 않을때 숫자만 처리하도록 하는 것
- numeric_only=

- numeric_only=
- include =
- 'all'입력된 모든 열이 결과에 포함된다.
- 데이터 유형의 목록 형태 결과를 지정된 데이터 유형으로 제한한다.
- 숫자 유형에 대한 결과를 제한하려면 numpy.number를 사용
- 객체 열에 대한 결과를 제한하려면 numpy.number를 사용하고,
- select_dtypes와 유사한 방식으로 문자열도 사용할 수 있다.
- pandas 범주형 열을 선택하려면 'category'를 사용한다.
- None(기본값), 결과에는 모든 숫자 열이 포함된다.

예시 1


- keep =
- 중복값이 있는 경우
- first : 첫 번째 등장하는 값들을 우선한다(기본값)
- last : 마지막 등장 값
- all : 중복된 값을 제거하지 않고 모든 값들을 선택. 이 경우 n보다 더 많은 항목들이 선택될 수 있다

all 사용시 8개로 더 많이 검출된다.
- errors=
- .drop() 에러 제어, 무시하고 진행

- .drop() 에러 제어, 무시하고 진행
- del 을 이용한 열 삭제
- 해당 데이터 주소로 찾아가서 del로 그 할당을 삭제한다.

- 해당 데이터 주소로 찾아가서 del로 그 할당을 삭제한다.
- how= : Na 발견시 제거되는 방식 설정
- NA 발견시 행 또는 열이 데이터프레임에서 제거되는 방식을 결정
- 'any' : 만약 NA 값이 하나라도 존재한다면, 해당 행 또는 열을 제거
- 'all' : 만약 모든 값이 NA인 경우에 해당하는 행 또는 열을 제거
- subset= : 특정열의 NA만 확인한다.
- method= :

- limit= : 연속되어 결측치가 나올 경우, 결측치 대체 횟수 지정

학습하면서 어려웠던 내용
- 방대한 양의 정보를얻어 혼란스럽고 이해한것 같지만 쓰려고하면 모르겠고,, 계속 찾아보면서 연습해야할 거 같다 :)
반응형
'데이터분석' 카테고리의 다른 글
| 29 Jupyter- DataFrame 심화 (0) | 2024.01.08 |
|---|---|
| 28. Jupyter- DataFrame (0) | 2024.01.08 |
| 26. Pandas (1) | 2024.01.04 |
| 25. 트랜잭션 및 SQL 고급 문법 (0) | 2023.12.30 |
| 24. JOIN (1) | 2023.12.29 |