- 오늘 데이터 분석을 하다가 로그 변환을 사용해봤는데요 사용 하는이유는
- 데이터의 비대칭성 개선
- 원본 데이터의 값들이 크게 치우쳐 있거나, 오른쪽으로 긴 꼬리를 가진 분포를 가질 때, 로그 변환을 하면
비대칭성이 줄어듭니다. - 로그 변환을 통해 데이터의 분포를 더 대칭에 가깝게 만들면, 평균과 표준편차를 사용한 통계적 분석이 더
정확해 집니다.
- 원본 데이터의 값들이 크게 치우쳐 있거나, 오른쪽으로 긴 꼬리를 가진 분포를 가질 때, 로그 변환을 하면
- 극단값(Outliers) 완화
- 로그 변환은 큰 값들을 상대적으로 줄여주기 때문에, 극단값이 분석결과에 미치는 영향을 완화시킬 수 있습니다.
- 데이터의 정규성(Normality) 개선
- 많은 통계적 기법들은 데이터가 정규분포(가우시안)를 따를 때 더 잘 작동합니다.
- 로그 변환을 사용하면 원래 비대칭적이거나, 양의 방향으로 치우친 데이터를 정규분포에 가깝게 만들 수 있습니다.
- 비율 분석에 유리
- 로그 변환은 데이터 간의 비율 차이를 분석할 때 유용합니다.
- 로그 값의 차이는 원래 값들 간의 비율 차이를 의미하기 때문
- 데이터의 비대칭성 개선
- 아래 사진은 예시 입니다.
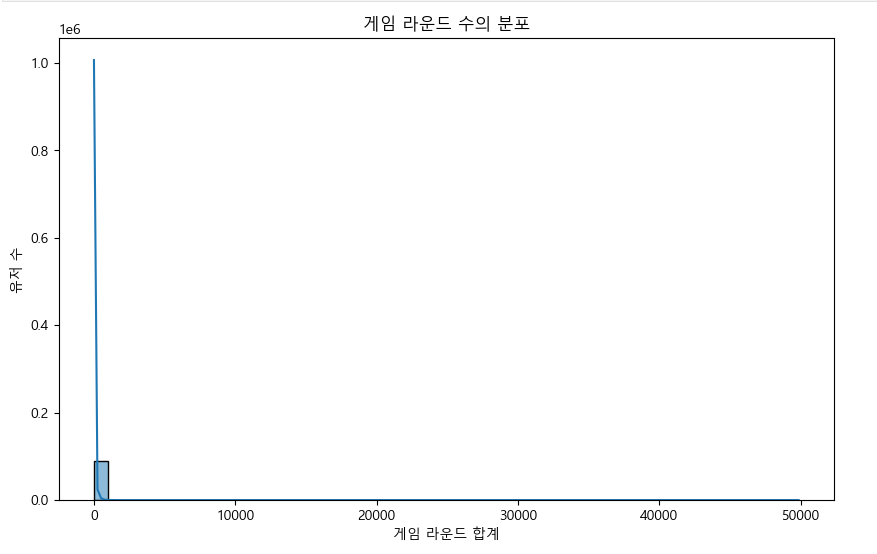

df['log_x'] = np.log1p(df['x'])사용 코드입니다. log1p 를 쓰는 이유는 log(1+x)를 계산하기에 데이터에 0 값이 있을 때 유용합니다.
반응형
'데이터분석' 카테고리의 다른 글
| 데이터 분석에서 자주 사용되는 대표적인 Use_Case(2) (4) | 2024.10.23 |
|---|---|
| 데이터 분석에서 자주 사용되는 대표적인 Use_Case(1) (3) | 2024.10.22 |
| 68. 가상 데이터 기반 A/B 테스트 분석 (0) | 2024.04.09 |
| 67-(3). A/B Test (0) | 2024.04.09 |
| 67-(2). A/B Test (1) | 2024.04.09 |