학습주제
- Colab이란?
- 머신러닝 기초와 배경
주요 학습 내용
- Colaboratory
- 웹 브라우저에서 Python을 작성하고 실행할 수 있게 해주는 클라우드 기반 구글의 서비스
- 원하는 부분 만큼의 코드를 실행하고 결과를 바로 볼 수 있는 인터렉티브 코드 실행 방식
- 코드 실험 및 분석에 용이 - 다양한 장점으로 많은 연구자 및 현업 개발자들의 사용
- 줄여서 Colab이라 부른다.
- Colab의 장점
- 좋은 접근성과 편의성
- 웹 브라우저만 있으면 어디서든 접근 가능하다.
- 별도의 파이썬 설치 및 환경 설정 없이 파이썬을 사용할 수 있다. - 무로 GPU 사용
- Colab은 사용자에게 무료로 GPU를 제공한다.
- 해당 GPU를 활용해 딥러닝 모델 학습 및 추론과 같은 과정에 유용하게 활용가능 - 다양한 라이브러리 지원
- 딥러닝 코드 작성에 필요한 다양한 패키지가 사전에 설치
- 별도의 설치 과정이 필요 없다.
- 좋은 접근성과 편의성
- 셀, Cell
- Colab에서 실행을 하는 가장 작은 단위
- 코드 셀과 텍스트 셀이 존재
- 코드 셀 : Python 코드를 작성하고 실행하는 공간
- 텍스트 셀 : 코드 설명 및 주석을 위한 공간으로 마크다운 형식의 텍스트를 써야한다. - 셀을 추가하기 위해서는 마우스를 원하는 위치로 이동, 경계선에서 목적에 따라 +코드 혹은 +텍스트를 선택한다

- 셀 실행 방법
- 코드 셀
- 마우스 : 실행 버튼 클릭
- 키보드 : shift + enter / ctrl + enter - 텍스트 셀
- shift + enter
- 다른위치 클릭
- 코드 셀
- 코드 셀 실행 시 변화
- 실행 버튼 위치의 숫자 생성
- 실행 colab 환경 동안 실행된 코드 셀의 순서를 나타낸다. - 코드 셀의 실행 결과가 셀 바로 아래 출력
- print 함수 혹은 계산 결과를 표현하는 경우 계산결과 출력 표시
- 명시적 출력이 없는 코드는 출력 없음
- 실행 버튼 위치의 숫자 생성
- Colab 에서 GPU 사용하기

런타임 유형 변경 클릭 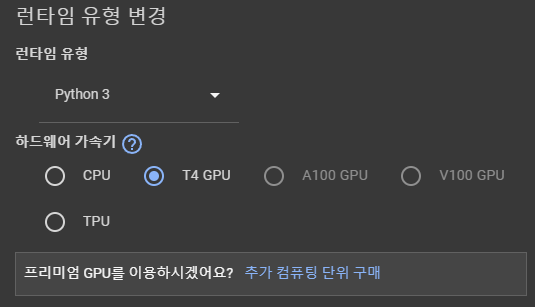
T4 GPU 클릭 후 적용 TPU는 과금모델
- 머신러닝
- 데이터에서 지식을 추출하는 작업
- 머신 스스로가 데이터를 바탕으로 그 안에 있는 특징과 패턴을 찾아낸다.
- 패턴을 찾는 일 : 학습 - 특징과 패턴을 바탕으로 새로운 데이터에 대한 추론을 진행
- AI, ML, DL
- AI : 기계가 사람의 지적 능력을 모방
- ML : 학습을 통해 (사람처럼) 예측을 진행
- DL : 사람을 따라한다면 사람의 인지과정을 모방하는 것이 가장 좋은방법
- DL ⊆ ML ⊆ AI
- 명시적 프로그램 : 규칙 기반 전문가 시스템 (Rule-Based Expert System)
- 머신 러닝 이전의 문제 해결 방법론
- 문제를 해결하기 위한 규칙을 수동으로 사전에 정의
- 규칙 : 하드 코딩 된 if-else 명령어 집합 - 대표적으로 스팸 메일 분류하는 과정이 해당된다.
- 특정 단어 (Sale, Win, Free 등)의 유무로 스팸을 분류 - 장점
- 처리 과정을 사람이 이해하기 쉽다.
- 작은 데이터에서 효과적이다. - 단점
- 특정 규칙은 한 분야나 작업에 국한된다.
- 변경에 대응이 어렵다
- 규칙 설계 시 해당 분야의 전문가가 필요하다.
- 머신러닝
- 명시적 프로그램의 한계를 극복할 수 있는 기법
- 데이터 내부에서 자주 발생하는 특징과 패턴을 감지
- 이런 특징과 패턴을 feature라고 한다. - 문제를 해결하기 위한 판단 기준을 시스템 스스로 찾아낸다.
- 장점
- 예상치 못한 상관 관계를 파악하는데 탁월하다
- 특정 도메인에서 전문가가 필수로 필요하지 않다. - 단점
- 머신이 패턴을 파악할 수 있도록 다양한 데이터가 필요하다
- 결과 분석 과정에서 사람이 이해할 수 없는 포인트가 존재할 수 있다.
- 머신 러닝의 활용 사례
- 추천, FaceID, 의료 영상 처리, 음성 처리, 금융 데이터 예측
- 머신 러닝 프로젝트의 흐름
- 문제정의
- 파이프라인, 모델 입/출력 - 데이터 확인
- 시각화, 특성 파악 - 데이터 분할
- 학습 / 검증 / 테스트, 편향성 확인 / 아웃라이어 제거 - 알고리즘 탐색
- 선행 연구 및 선행 프로젝트 참고 - 데이터 전처리
- 알고리즘 고려, 선행 과정 참고 - 학습과 검증
- 최적 모델 탐색, 반복 작업 - 최종 테스트
- 테스트 데이터 활용, 보고 - 시스템 런칭
- 모니터링, 유지 보수
- 문제정의
- 메타 데이터(Meta Data) 와 레이블(Label)
- 메타 데이터 : 주어진 기본 데이터에 추가적으로 제공하는 정보
- 데이터의 출처, 형식, 위치 등 데이터 간의 관계와 구조를 파악하거나
- 데이터의 속성, 특성, 분류 등 데이터의 내용을 설명한다 - 레이블 : 특정 문제에 해당하는 데이터의 설명 혹은 답변
- 분류를 하는 문제라면 데이터가 속할 범주
- 목표 값을 찾는 회귀 문제라면 데이터가 표현할 특정 숫자 등 - 대부분 사람이 직접 생성해줘야 하는 경우가 많다
- 혹은 타겟(taget)이라고 부르기도 한다.
- 메타 데이터 : 주어진 기본 데이터에 추가적으로 제공하는 정보
- 지도 학습 (Supervised Learning)
- 정답 레이블 정보를 활용해 알고리즘을 학습하는 학습 방법론
- 데이터와 정답인 레이블 사이의 관계를 파악하는 목적을 갖는 알고리즘 학습.
- 정답이 존재하므로 모델이 풀어야하는 문제가 비교적 쉽고 잘 학습된다.
- 명확한 평가 수치가 존재하며 학습된 모델의 성능을 쉽게 측정할 수 있다.
- 정답이 필요하므로 이를 위해 추가적인 시간 / 노동 / 비용이 필요하다
- 정답을 매기는 행위에 필요한 전문 인력과 같은 추가 비용이 발생한다.
- 비지도 학습 (Un-Supervised Learning)
- 정답 레이블 정보가 없어 입력 데이터만을 활용해 알고리즘을 학습하는 학습 방법론
- 데이터 내부에 존재하는 패턴을 스스로 파악하는 목적을 갖는 알고리즘 학습.
- 정답을 따로 준비할 필요가 없으므로 비용적인 이점이 있다
- 사용자가 의도한 패턴 이외의 새로운 패턴을 찾을 가능성이 있고 창작과 같은 다양한 활용 분야에 사용할 수 있다.
- 학습된 모델의 성능을 측정하기 위한 기준이 없어 결과 해석이 주관적일 수 있다.
- 신뢰할 수 있는 결과를 얻기 위해 다수의 데이터가 필요하다.
- 준지도 학습 (Semi-Supervised Learning)
- 일부의 데이터만 정답이 존재, 다수의 데이터에는 레이블이 없는 상황에서 알고리즘을 학습
- 지도 학습과 비지도 학습의 특징을 일부 차용하여 일부 레이블링된 데이터로 특성을 파악하고 레이블링 되지 않은 데이터로 전체 데이터의 패턴을 파악하는 방식으로 학습이 진행되는 알고리즘 학습.
- 레이블이 부족한 데이터셋에서 유용하다
- 많은 데이터를 활용할 수 있으므로 일반화 성능을 향상시킬 수 있다.
- 품질이 낮은 레이블이나 데이터가 존재에 특히 취약할 수 있다.
- 알고리즘의 복잡성이 증가하며, 구현 및 활용에 어려움이 있을 수 있다.
- 자기 지도 학습 (Self-Supervised Learning)
- 정답이 하나도 없는 데이터에서, 정답을 강제로 생성 후 학습하는 학습 방법론
- 데이터 내부를 강제로 훼손 후 복원하는 방법을 주로 사용, 특정 데이터 내부의 성질을 파악하는데 사용된다.
- 만들어진 데이터를 가지고 다른 문제 해결에 이용한다
- 레이블 없이 데이터의 특징을 파악할 수 있다.
- 다양한 데이터에 활용 가능하다.
- 목적하는 문제를 직접적으로 해결하는 것이 아니므로 N회 이상의 추가적인 학습 과정이 필요 할 수 있다.
- 알고리즘이 잘못된 패턴을 학습할 위험이 있다.
- 강화 학습 (Reinforcement Learning)
- 어떤 환경에서 상호작용하는 에이전트가 보상을 이용해 특정 행동을 하도록 유도하는 학습 방법론
- 알파고 같은 고급 방법
공부하면서 어려웠던 점
- -
반응형
'데이터분석' 카테고리의 다른 글
| 47-(1). 지도학습과 대표 알고리즘 (1) | 2024.02.02 |
|---|---|
| 46-(2). 통계 개념과 용어 (3) | 2024.02.01 |
| 45. Tableau (3) | 2024.01.31 |
| 44. 다양한 시각화 툴 (1) | 2024.01.30 |
| 43. 지표의 이해와 좋은 지표란? (3) | 2024.01.30 |