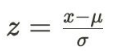2000년과 2020년 NASDAQ 시총 상위 기업을 보면 '제조업'에서 '서비스'로 흐름이 바뀌고 있다.
FAANG중 애플을 제외한 모든 기업은 제조업이 아닌 서비스기업이다(애플도 완전 제조업은 아님)
즉 데이터를 이용한 가치가 중요
데이터 분석이란?
데이터를 "정리,변환 조작, 검사" 하여 "인사이트"를 만들어내는 작업이다.
데이터 분석으로 무엇을 할 수 있는가? 왜 해야하는가? -> 의사 결정의 판단 기준이 '주관적인 직감'에서 '객관적인 데이터'로 바뀐다.
하지만 꼭 해야할까?
데이터가 없는경우?
데이터가 주어진 문제와 관련없는 경우?
데이터가 주어진 문제를 해결하는데 결국 도움을 주지 못한다면 ?
=> "주어진 데이터로 문제를 해결할 수 있을지 없을지 가늠하는 것도 데이터 분석"
단순한 분석보다는 문제를 해결할지 고민하는게 더 중요하다
데이터 분석 프로세스
문제 정의
풀고자 하는 문제가 명확하지 않으면 데이터 분석은 무용지물 된다. a. 큰 문제(main objective)를 작은 단위의 문제들 (sub objective)로 나눈다 b. 각 작은 문제들에 대해서 여러 가설들을 세운다. c. 데이터 분석을 통해 가설을 검증하고 결론을 도출하거나 피드백 반영한다.
궁극적으로 해결하고자 하는문제(달성목표)가 무엇인가?
해당 문제를 일으키는 원인이 무엇인가?
상황을 판단하는 지표나 기준이 무엇인가?
데이터 수집
검증해보고자 하는 가설을 해결해줄 데이터를 수집한다. a. 가설 검증에 필요한 데이터가 존재하는가? => 데이터가 가설 검증에 부절적하거나 없을 수도 있다. b. 어떤 종류의 데이터가 필요한가? => 데이터로부터 얻고자 하는 정보가 무엇인지 명확하게 해야 필요한 데이터만 모을 수 있다. c. 얻고자 하는 데이터의 지표가 명확한가? => 적절해 보이는 데이터라도 지표가 부적절하면 가설 검증 및 결론 도출시 오류를 범할 수 있다.
데이터 전처리
데이터 추출, 필터링, 그룹핑, 조인등 (SQL 및 DB) 데이터 분석을 위한 기본적인 테이블을 만드는 단계 테이블과 칼럼의 명칭, 처리 / 집계 기준, 조인시 데이터 증식 방지한다.
이상치 제거, 분포 변환, 표준화, 카테고리화, 차원 축소 등 (Python / R) 수집한 데이터를 데이터 분석에 용이한 형태로 만드는 과정이다.
데이터 분석
탐색적 데이터 분석 (EDA) a. 그룹별 평균, 합 등 기술적 통계치 확인 b. 분포확인 c. 변수 간 관계 및 영향력 파악 d. 데이터 시각화
모델링 (머신러닝, 딥러닝) a. Classification (categorical label) b. Regression (numerical label) c. 클러스터링(비지도학습)
리포팅 / 피드백
내용의 초점은 데이터 분석가가 아닌 상대방이다. a. 상대가 이해할 수 있는 언어 사용 b. 목적을 수시로 상기, 재확인
적절한 시각화 방법 활용 a. 항목간 비교시 원 그래프는 지양하고 막대 그래프 위주, x,y축 및 단위를 주의 b. 시계열은 라인이나 실선으로 표현 c. 분포는 히스토그램이나 박스플롯 d. 변수간 관계는 산점도로 표현
Colab 소개
Colab은 클라우드 기반의 Jupyter 노트북 개발 환경입니다.
웹 브라우저에서 텍스트와 프로그램 코드를 자유롭게 작성할 수 있는 일종의 온라인 텍스트 에디터
CPU와 램을 제공해주기 때문에 컴퓨터 성능과 상관없이 프로그램을 실습할 수 있다.
Colab 파일을 노트북(.ipynb)라고 부르며, 코드를 입력하는 곳이 코드 셀이라 한다.
데이터에서 하나의 instance(sample)는 그것이 가진 여러 속성값들을 이용해서 표현이 가능하다.
속성값 (feature) 들간의 크기 및 단위가 들쭉 날쭉 하거나 가지는 값의 범위가 크게 다른 경우, 혹은 이상치(outlier)문제가 심각한 경우 데이터 분석, 머신러닝, 딥러닝 방법을 적용하기 어려워지는 경우 있다.
이때 정규화와 스케일링을 통해 feature들이 가지는 값의 범위를 일정하게 맞춰주는 과정이 필요하다.
Normalization(정규화)
여러가지 값(feature)들이 가지는 범위의 차이를 왜곡하지 않으면서 범위를 맞추는 것
Min-max normalization - 모든 feature 값이 [0, 1] 사이에 위치하도록 scaling하는 기법이다. - 분모는 feature가 가질 수 있는 maximum값과 minimum값의 차이로 두고, 분자는 해당 feature 값과 minimum 값의 차이로 둔다. - feature들간의 variance 패턴은 그대로 유지한 채로 feature가 scaling되게 된다. - 다르게 이야기하면, 특정 feature만 variance가 매우 큰 경우, 특히 이상치가 존재하는 경우 여전히 feature간의 scaling이 데이터 분석에 적절하지 않을 수 있다.
Z-score normalization(Standardization) - Feature 값들이 μ(평균)=0, 𝝈(표준편차)=1 값을 가지는 정규분포를 따르도록 스케일링합니다.
- Feature값을 평균값으로 뺀 후 표준편차값으로나눈 값을 사용합니다 이때 z 값을 표준점수(z-score) - Outlier 문제에 상대적으로 robust한 스케일링 방법입니다 - min-max normalization처럼 feature값이 가지는 최소값-최대값 범위가 정해지지 않는 단점이 있습니다 - 대부분의 머신러닝 기법(선형회귀, 로지스틱 회귀, SVM, Neural Networks)들을 활용하는 경우 input에 standardization를 적용해야하는경우가 많습니다 - Gradient descent를 활용한 학습 과정을 안정시켜주고빠른 수렴을 가능케 합니다 - z-score가 ±1.5𝝈, ±2𝝈를 벗어나는 경우 해당 데이터를 이상치로 간주하고 제거할 수 있습니다
Log scaling - Feature 값들이 exponential 한 분포(positive skewed)를 가지는 경우 feature 값들에 log 연산을 취하여 스케일링할 수 있습니다. - 비슷하게 square root 연산을 취하거나 반대의 분포를 가지는 경우 power / exponential 연산을 통해 스케일링해볼수 있습니다. - 다양한 스케일링을 통해 데이터가 좀더 정규분포에 가까워지도록스케일링하며 outlier 문제에도 좀 더 적극적으로 대응 가능합니다.