학습주제
- 문자열 제어
- DataFrame 재구성
- DtatFrame 결합과 병합
- 시계열 제어
주요 학습 내용
- .str
- 문자열 메소드를 실행할 때는, .str이 먼저 나온다고 생각하자
- Series와 Index에 대한 벡터화된 문자열 함수이다.
- 반복문을 사용하지 않고도 간단하게 문자열 데이터를 처리할 수 있다.
- 특정한 메서드에서 다르게 처리하지않는 한 NA 값은 NA 상태로 유지된다.

- .str.upper(), .str.lower()
- 대문자, 소문자 변경

- 대문자, 소문자 변경
- .str.contains(pat)
- Series.str.contains(pat, case=True, flags=0, na=None, regex=True)
- 문자열 Series 또는 Index에서 주어진 패턴 또는 정규식이 포함되어 있는지 확인한다.
- 주어진 문자열이나 정규식이 다수의 문자열 요소에 대해 포함 여부를 효과적으로 확인한다.

- .str.startswith(), .str.endswith()
- 시작이나 끝에 () 포함하는 단어 검색하는 기능

- 시작이나 끝에 () 포함하는 단어 검색하는 기능
- .str.replace() : 문자 변경

- .transpose()
- 전치행렬 : 행과 열을 교환하여 얻는 행렬, 주대각선을 축으로 반사 대칭을 한다.
- 행과 열을 반전시키면 된다.
- 1 3 5 1 2
2 4 6 => 3 4 ( 1, 4 위치 대각 고정후 반전)
5 6 - 줄여서 .T로 사용가능하다
- 전치행렬 2번 != 원본
- 전치 2번했더니 모든 열의 dtype이 object로 변경되었다. 열의 데이터 타입을 일치 시켜야하기에 문자열로 변환
-> 모든 데이터 웬만하면 문자열로 가능하기 때문이다.
- .stack()
- 데이터프레임의 구조를 재조정하는데 유용하다
- columns에 다중 인덱스가 있는 데이터프레임에서 사용하면 컬럼 인덱스가 로우 인덱스 레벨로 이동한다.
- 컬럼을 로우로 "압축"하는 작업을 수행한다.

- melt()
- 넓은 형식으로 구성된 데이터프레임을 긴 형식으로 변환하여 데이터를 재구성
- 함수를 사용하면 하나 이상의 열을 식별자 변수(id_vars)로 설정하고, 나머지 열인 측정 변수(value_vars)를
행 방향으로 언피벗하여 두 개의 비식벼랒열인 varialbe과 value만 남게되는 형태로 데이터 프레임을 변환.
- .concat()
- 결합,연결
- 데이터프레임을 결합, 연결하는 함수
- default는 행 방향 연결, 인덱스 유지
- 파라미터 정보 : https://pandas.pydata.org/docs/reference/api/pandas.concat.html

- Inner Join / Left Join / Right Join
- merge() 메소드를 이용한다.
- .merge()
- 일반적으로 pandas.merge(), pd.merge()가 쓰인다.
- 파라미터 정보
1. pandas : https://pandas.pydata.org/docs/reference/api/pandas.merge.html
2. DataFrame : https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.merge.html
- Outer Join
- merge()메소드를 이용
- 두 개의 DataFrame을 Left, Right로 둘 때 Left를 기준으로 조인하는 방법이다.
- https://pandas.pydata.org/docs/user_guide/merging.html#brief-primer-on-merge-methods-relational-algebra
- pd.Timestamp()
- 날짜 / 시간 표현하는 데이터
- https://pandas.pydata.org/docs/reference/api/pandas.Timestamp.html

- Python의 날짜 / 시간 포맷
- pd.to_datetime()
- 문자열 또는 숫자를 날짜와 시간으로 변환하는 기능을 제공한다.
- 날짜 인자 입력 방법은 위의 Timestamp()와 거의 같다.
- https://pandas.pydata.org/docs/reference/api/pandas.to_datetime.html

- pd.DatetimeIndex()
- 날짜와 시간 데이터를 인덱스로 사용하기 위한 특수 데이터 구조
- 시계열 데이터를 쉽게 조작하고 분석하도록 도와준다.
- pd.date_range(시작일, 종료일 날짜 간격)
- 날짜 범위를 생성하는 함수
- 파라미터 : https://pandas.pydata.org/docs/reference/api/pandas.date_range.html

- Offset aliases
- 다양한 시계열 빈도에 대해 유용한 문자열 별칭이다.
- 원하는 빈도에 맞게 데이터를 처리하고 분석할 수 있다.
- https://pandas.pydata.org/docs/user_guide/timeseries.html#offset-aliases
- Period aliases
- 다양한 일반적인 시계열 빈도에 대해 유용한 문자열 별칭
- 원하는 빈드로 기간을 설정하고 분석하는 데 유용하다
- Anchored offsets
- 일부 빈도에서 앵커링 접미사를 지정할 수 있는 기능이다.
- Timedelta : 간격, 시간차이
- 시각 - 시각 = 시간차이
- 시간차 + 시간차 = 시간차이
- 시간차 - 시간차 = 시간차이
- to_timedelta()
- timedelta_range()
- 날짜 / 시간 속성 접근자.dt
- 시리즈에서 날짜와 시간과 관련된 속성에 접근할 때 사용되는 기능이다.
- 속성 : https://pandas.pydata.org/docs/reference/series.html#datetime-properties
- 메소드 : https://pandas.pydata.org/docs/reference/series.html#datetime-methods
- .dt로 속성 접근
- Timestamp의 메소드와 속성
- 재색인(reindex)
- 인덱스를 새로운 인덱스로 변경하거나 재정렬하는 작업
- 데이터를 새로운 인덱스에 맞게 재배열하거나 누락된 값을 처리하는 데 유용하다.
- 시리즈 데이터 프레임 모두 가능하다.

- 재샘플링(resample)
- 시계열 데이터의 주기를 변경하는 작업
- 재샘플링 유형
- 다운 샘플링 : 데이터(빈도)를 더 낮은 주기로 설정
- 업 샘플링 : 데이터 빈도를 더 높은 주기로 설정
- 보간(Interpolation)
- 주어진 데이터 사이에 누락값을 추정하는 방법
- 선형 보간, 최근접 이웃 보간, 다항식 보간 등
- .asfreq()
- 업샘플링 시에 사용되는 함수
- 주어진 주기에 맞게 데이터를 새로운 인덱스로 재구성
- 누락된 데이터를 NaN 값으로 채운다.
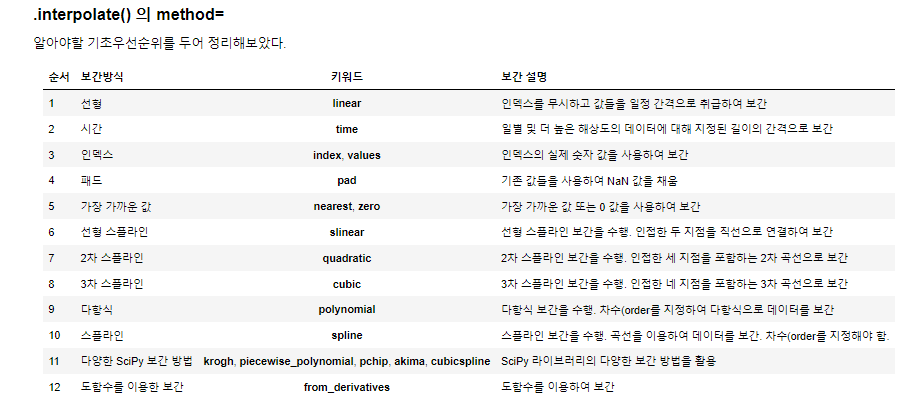
- .interpolate()
- 업샘플링 시에 사용되는 함수, 보간을 수행하여 누락된 값을 추정한다.
- method 매개변수를 사용하여 다른 보간 방법을 선택한다.

공부하면서 어려웠던 점
- 이렇게 기본적인 속성, 메소드와 jupyter_note북 사용법을 배웠는데 차차 프로젝트 하면서 익혀가야할 것 같다.
반응형
'데이터분석' 카테고리의 다른 글
| 32-(1). 확률과 통계 (2) | 2024.01.14 |
|---|---|
| 31. 정규화, 데이터 스케일링 (2) | 2024.01.10 |
| 29 Jupyter- DataFrame 심화 (0) | 2024.01.08 |
| 28. Jupyter- DataFrame (0) | 2024.01.08 |
| 27. Jupyter 사용 (1) | 2024.01.08 |